AI Neuroscience
I have spent half of my weekends browsing books in church street bookstores in bangalore. I could go on for four five hours picking titles, reading backcovers, author stories and collecting everything I wanna have.
During one of these visits I found “The Web of Life” by Fritjof Capra. I read the book in a month and since then I started studying complex systems. Complex systems seem to like answer to everything. Newton’s Mechanics, relativity, number theory all seem subsets of this subject. I got lusted away by complex systems :p I got into habit of trying to model everything as complex system.
I am AI engineer by profession, I have built and trained transformer models since before chatGPT came. I now wanted to solve these deep models using complex system theory. Half of my active research projects are on this.
While reading on “solving neural networks” I came across Mech Interp community. I sat and scoured neuropedia in 4 hours; and noted down everything I explored along with it here below.

You too must have gotten this thought — “can we not map each of the concepts we know to individual neurons? Brain experts have already figured out which areas of the brain are responsible for speech, which ones for creative thinking, which ones for vision — then it must be possible to figure out what is responsible for the color red, what for the word notebook.”
And if neural networks are almost similar to brains, then the same must be possible for neural networks too. And we don’t even have any issues probing neural networks again and again; we could not do the same for brains. Doctors had to wait for the perfect patient to come, who has some part of the brain damaged. We can on purpose damage different parts of neural networks and check what works and what doesn’t. It seemed like a jackpot. We should be able to figure it all out quickly. Some one must have tried it. Yes, OpenAI did.
In May 2023, OpenAI published “Language models can explain neurons in language models” (Bills et al., 2023). They used GPT-4 to look at the activations of neurons in GPT-2 and write English explanations of what each neuron seemed to fire for. They scored the explanations by asking GPT-4 to predict the neuron’s activation on held-out text using only the explanation, and seeing how close that prediction came to the real activation.
It worked, sort of. They got readable explanations for a non-trivial fraction of neurons. They open-sourced the entire dataset of neuron explanations for GPT-2.
But the underlying picture was uncomfortable. A lot of neurons just didn’t have a clean explanation. They would fire on inputs that looked unrelated — a neuron that responded to French words and mathematical inequalities and legal phrases. The hypothesis that each neuron has one job — monosemanticity — clearly wasn’t holding.
So why not? Why do neurons mix concepts?
- Paper: Language models can explain neurons in language models (OpenAI, 2023)
- Code + data: openai/automated-interpretability
From this we figured that one neuron doesn’t do one thing — it is doing a bunch of things, but it is also not doing anything by itself. Functionality is spread across. A few neurons together are responsible for a feature, and one neuron is responsible for lots of things, but only partially. So we designed an experiment to take this into account and figure out what all partial concepts a neuron represents.
In their 2022 paper “Toy Models of Superposition” (Elhage et al.), they showed that when a network has more features it wants to represent than it has neurons to dedicate to each one, it packs multiple features into the same neuron — provided those features are sparse enough to rarely co-occur.
This is superposition. It is the reason individual neurons are hard to interpret: each one is a linear combination of several actual features. Polysemanticity isn’t noise. It’s compression.
Once you have this framing, the interpretability problem changes shape. The right unit of analysis isn’t the neuron — it’s the feature direction in activation space. You need a way to recover those feature directions from the superposed soup the neurons present.
Paper: Toy Models of Superposition (Anthropic, 2022)
Borrowing an old idea from neuroscience.
The fix turned out to be sparse coding — an idea originally from neuroscience. Bruno Olshausen and David Field showed in 1996 that if you train a network to reconstruct natural images using a sparse linear combination of basis functions, the basis functions you get out look like the receptive fields of neurons in the primary visual cortex (V1). Olshausen later founded the Redwood Center for Theoretical Neuroscience at UC Berkeley, which has been one of the homes of sparse coding ever since.
Three decades later, that same trick was applied to LLM activations.
The first paper to do it for language models was “Sparse Autoencoders Find Highly Interpretable Features in Language Models” (Cunningham, Ewart, Riggs Smith, Huben, Sharkey, 2023) — independent researchers and Apollo Research. They trained a Sparse Autoencoder (SAE) on the activations of a layer of a small LLM. An SAE is a wide-but-sparse bottleneck: it takes the dense activation vector, expands it into a much larger dictionary, and forces only a few entries in the dictionary to fire for any given input. The dictionary entries it learns — the SAE features — turn out to be far more monosemantic than the original neurons.
Anthropic followed within weeks with “Towards Monosemanticity” (Bricken et al., 2023), which scaled the approach on a one-layer transformer and showed many cleanly interpretable features. Then “Scaling Monosemanticity” (Templeton et al., 2024) ran it on Claude 3 Sonnet itself — they found a feature for the Golden Gate Bridge, features for code errors, features for sycophancy. You could steer the model by clamping a feature on, and watch its outputs shift.
SAEs are the current state of the art for separating superposed features. They are not perfect — there is active debate about whether they find “canonical” feature directions or just one of many possible decompositions (see Leask et al., “Sparse Autoencoders Do Not Find Canonical Units of Analysis”, 2025) — but they are the best tool we have.
- Cunningham et al., Sparse Autoencoders Find Highly Interpretable Features (2023)
- Bricken et al., Towards Monosemanticity (Anthropic, 2023)
- Templeton et al., Scaling Monosemanticity (Anthropic, 2024)
- Leask et al., SAEs Do Not Find Canonical Units of Analysis (2025)
- Sparse coding origins: Olshausen & Field, Emergence of simple-cell receptive field properties by learning a sparse code for natural images (Nature, 1996)
- Open SAE suite: Gemma Scope (DeepMind, 2024) — 400+ SAEs on Gemma 2
This experiment worked. Now we have a way to separate the concepts. Another sister experiment was to trace the circuit — figuring out the exact path from input to output.
Once you have clean features, you can trace what the model does with them.
Separating features is one half of the problem. The other half is: how does the model use them? Which feature triggers which other feature? What is the computational graph that runs when the model produces a particular output?
This is circuit tracing, and Anthropic’s May 2025 release is the current reference work. They built a method that takes a prompt + completion and produces a graph of which features at which layers are causally responsible for the output. You can see the model think.
The released work comes with open-source tooling — a circuit tracer library — that lets external researchers run the same analysis on their own SAEs.
- Anthropic, Circuit Tracing (May 2025)
- Open-source library: decoderesearch/circuit-tracer
- The conceptual foundation: Elhage et al., A Mathematical Framework for Transformer Circuits (Anthropic, 2021)
The next problem is scale. There are millions of features. Who labels them all?
Once you have SAEs producing hundreds of thousands of features per layer, you need an automated way to name them. The pipeline is called auto-interpretation — sometimes shortened to auto-interp or verbalised features.
The idea is straightforward: take the inputs on which a feature fires most strongly, pass them to an LLM, ask the LLM what they have in common, and use that as the feature’s label. The output is a one-line natural-language description per feature, plus a confidence score.
The lineage goes back to OpenAI’s Bills et al. (Act 1) — they did this for raw neurons. The current version, applied to SAE features instead, was popularised by Anthropic’s Scaling Monosemanticity and then opened up by EleutherAI and others.
- EleutherAI / Caden Juang et al., Open Source Automated Interpretability for Sparse Autoencoder Features (2024)
- Neuronpedia — interactive browser for SAE features with auto-interp labels
- Goodfire AI — productionised SAE tooling and labelling pipelines
(If there is an earlier or more specific “verbaliser” paper I’m missing here, janhavi — drop the link and I’ll splice it in.)
So I picked the smallest open model that still has interesting middle layers — Gemma 2 2B — and ran the whole pipeline on an M3 MacBook. No cluster, no remote GPU. The point was to feel where each step actually pinches.
Step 1 — get the model loaded and map its insides. Gemma 2 2B is 26 decoder layers, residual width 2304, GeGLU MLPs, grouped-query attention with alternating sliding-window / full masks. I annotated every shape end-to-end so I could pick a layer to attack without guessing what lives where. Layer 12 — middle of the stack — is where I put the hooks.
→ Gemma 2 2B architecture — every tensor shape
Step 2 — watch the answer crystallize across layers. Before training any SAE, I wanted a feel for when the model decides what to say. The logit lens trick: take the residual stream at every layer, run it through the final RMSNorm and lm_head, and read the top-5 predicted next tokens at each layer. You watch the answer wobble in the middle layers and lock in around layer 20-something.
→ Logit lens — top-5 predictions at every layer, for a handful of prompts
What’s interesting is that most of the eventual top-1 tokens are already in the top-3 or top-4 by layer 12–14, and then climb to rank 1 by the end. The middle layers know roughly what the answer is; the later layers are sharpening, not deciding.
Step 3 — harvest activations. Forward hook at layer 12, ~500k tokens of OpenWebText / The Pile mix, dump to .npy on disk. Final shape: [500_000, 2304] in bf16. About 2 GB on disk. The harvest itself took a couple of hours on the MPS backend.
Step 4 — train a TopK SAE. Dictionary size 8× the residual dim → 18,432 features. k = 32 (each token activates exactly 32 of those 18,432 features). Unit-norm decoder rows, AdamW, batch 4096. 5000 steps, ~73 minutes wall time on the laptop.
→ TopK SAE architecture — shapes, losses, constraints → Full training report — curves + diagnostics
What I got at the end:
| metric | value |
|---|---|
| explained variance | 78.4% |
| normalized MSE | 0.216 |
| L0 (avg active features / token) | 32 (exact, by TopK construction) |
| dead features (no fires in 50k-token sample) | 67 / 18,432 (~0.36%) |
| wall time | 73 min on M3 |
That’s not state-of-the-art — Gemma Scope hits higher EV at this layer with much bigger dictionaries and much more compute — but it’s a real, working SAE on a real model, trained on a laptop in an afternoon. The headline curves:
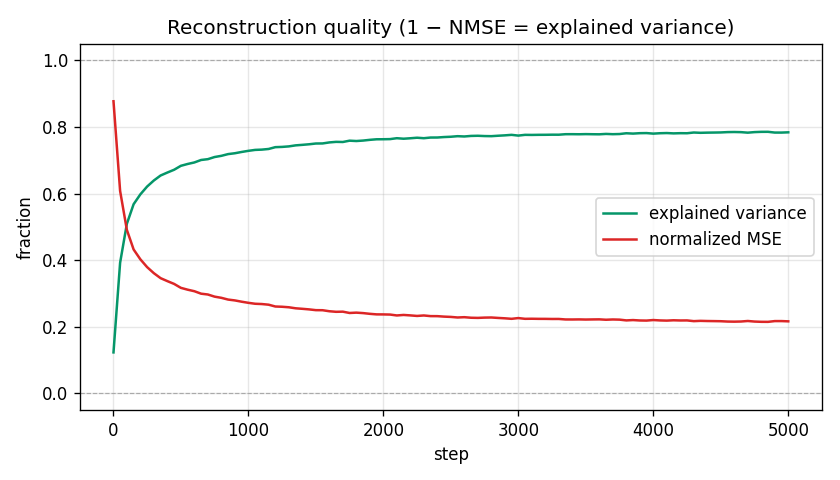
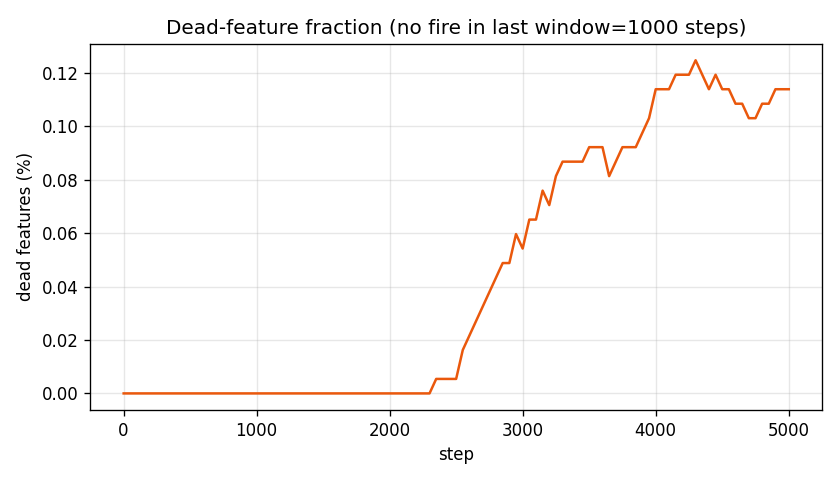
The dead-feature curve is the one to watch when you scale up dictionaries — for 8× it stayed under half a percent, but at 32× or 64× this is the failure mode you spend all your time fighting.
Step 5 — see what the features actually fire on. For each feature in the dictionary, I ran another 200k tokens through the SAE and collected the top-20 contexts that activated it hardest, with the firing token bracketed [[like this]]. This is the rawest, most useful artefact of the whole project — millions of features can be cheap-labelled by just looking at what fires them.
A few I found that have visibly clean meanings:
- virology / HBV biology — fires on tokens like
RNA,capsid,pgRNA,viral particle, but only inside passages discussing hepatitis B virus replication. Same surface tokens in other contexts don’t fire it. - London landmarks & historic buildings — Tower of London, Westminster, St Paul’s, Christopher Wren, Regent’s Canal. Tourist-guide prose lights this one up.
- legal / sentencing language — “the trial court allowed”, “sentence affirmed in part”, “Defendant-Appellant”. Court-opinion register, not just the word “court”.
- Norwegian / Scandinavian text — fires on tokens of Norwegian prose. Crisp language-ID feature.
- quantum-mechanics jargon —
ancillas,wavefunctions,interferometer,non-classical entanglement. Sits cleanly in physics passages. - aircraft model designators — F-104A, F-4C, X-15. Fires on the letter-number patterns only inside aircraft-listing contexts; doesn’t trigger on every alphanumeric.
There’s also a long tail of less satisfying features — ones that look like “tokens that follow ###” or “the apostrophe in possessive ‘s after a place name”. Those are the syntactic / positional features the SAE finds first, and they’re a bit meh. The semantic ones above are the interesting ones.
The corpus matters here: my 500k-token harvest happens to lean heavy on London tourism guides, HBV virology papers, court opinions, and Norwegian news, so the features mirror that. Train on a different corpus and a different feature alphabet would emerge.
Step 6 — what’s next. The SAE is a side-hook: it lets me read the residual stream at layer 12 but it doesn’t tell me which features cause which other features. To get that, I’d swap the MLP itself for a learned transcoder — same TopK shape, but trained to predict the MLP’s output, not just reconstruct the residual stream. Once you have transcoders at every layer, the decoder weights form a feature-to-feature graph and you can do real circuit tracing.
I haven’t trained one yet, but I’ve sketched the architecture parallel to the SAE so the training code is mostly a one-line swap:
→ Transcoder architecture — what changes vs the SAE
That’s the natural next step, and where Act 4 (circuit tracing) plugs in.
The state of it
Five years ago, the question was: can we read what a language model is doing? The honest answer was no.
Today the answer is: partially, and getting better quickly. We can take a model, train SAEs on its layers, label the features automatically, trace which features cause which outputs, and steer behaviour by clamping features on or off. None of this is a complete solution — SAEs may not find canonical features, circuit tracing is computationally heavy, auto-interp labels are noisy — but the loop is closed.
The field’s main open problems are documented in “Open Problems in Mechanistic Interpretability” (Sharkey, Conmy, McGrath et al., 2025) — arxiv.org/abs/2501.16496. Read this if you want to know where to push next.
The people doing this work
| Person | Org | Why they matter |
|---|---|---|
| Chris Olah | Anthropic (Head of Interpretability, co-founder) | Invented mechanistic interpretability as a field. Distill.pub Circuits thread. |
| Neel Nanda | Google DeepMind (Mech Interp Team Lead) | Built Gemma Scope, runs MATS streams, the most accessible front door to the field. |
| Arthur Conmy | Google DeepMind | MATS empirical interpretability stream mentor. Co-author on Open Problems. |
| Lee Sharkey | Apollo Research (CSO) | Lead author on Open Problems. Early SAE work. |
| Marius Hobbhahn | Apollo Research (CEO, co-founder) | Solved Stephen Casper’s public challenges → MATS → founded Apollo. The model trajectory. |
| Stephen Casper | MIT CSAIL | Posts public mech interp challenges. Co-author on Open Problems. |
| Joseph Bloom | Decode Research / Independent | Co-author with Nanda and Conmy on attention SAEs. Proof you don’t need an institution. |
| Tom McGrath | Anthropic + Goodfire AI (co-founder) | Goodfire AI runs SAE hackathons with Apart. Co-author on Open Problems. |
| Jesse Hoogland | Timaeus (founder) | Invented “developmental interpretability” as a subfield. |
| Evan Hubinger | Anthropic (Alignment Science) | Mentors MATS scholars at Anthropic. Deceptive alignment focus. |
| Trenton Bricken | Anthropic | First author on Towards Monosemanticity. |
| Adly Templeton | Anthropic | First author on Scaling Monosemanticity. |
| Hoagy Cunningham | Apollo Research | First author on the original SAE-for-LLMs paper. |
| Bruno Olshausen | UC Berkeley / Redwood Center for Theoretical Neuroscience | The 1996 sparse coding paper that everything in Act 3 traces back to. |
Where to read more
- transformer-circuits.pub — Anthropic’s interpretability research hub. Most of Acts 2, 3, 4, 5 live here.
- Neuronpedia — browse SAE features interactively.
- LessWrong / Alignment Forum — where current debates happen.
- Distill Circuits thread — pre-LLM mech interp on vision models. Origin of the modern toolkit.
- ARENA curriculum — practical curriculum to learn the tools.
An interesting watch:
How brains were first read
A French doctor in 1861 had a patient who could speak only one word, “Tan”. He could perfectly understand speech but could speak nothing but “Tan”. Doctor checked his brain after he died and found his left frontal lobe damaged. Doctor concluded that area controls speech production in humans. It is called Broca’s area.
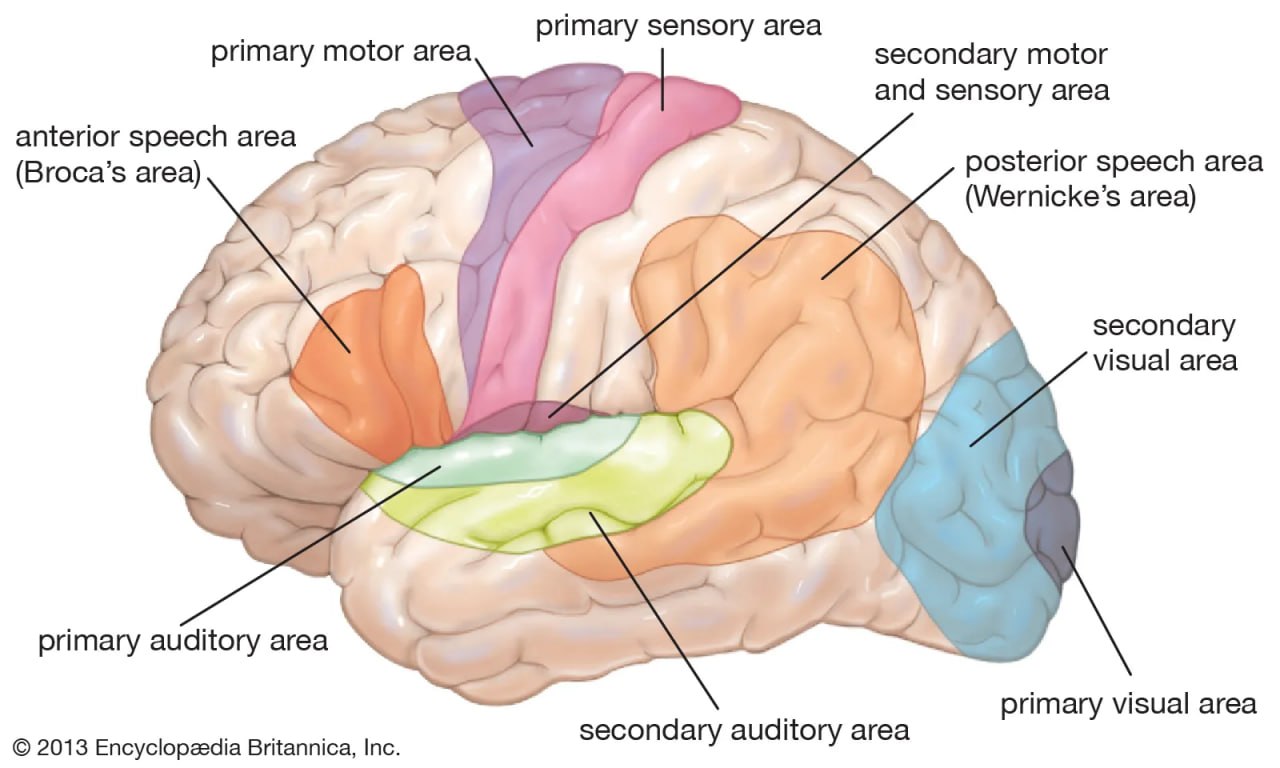
For years, neuroscientists studied brain using this rudimentary method. They will get lucky with patients who have parts of brains damaged; they would test those people and come across such bizarre quirk and conclude that part is responsible for so and so.
Almost till 1970ish. Right now we make people do things like speak and take their MRI scans to point brain activity regions.
We can’t freely turn on/off people’s brains and test hypothesis. But we can do it on neural networks.
That is what AI neuroscience is about. Engineers probe neural networks, again and again at different areas and check which part is doing what.
v1, 2026-05-24. Open gaps to fill: the specific “verbaliser” paper janhavi had in mind; confirmation that the Cunningham SAE paper authors I listed are correct; whether to add a section on steering as a separate act.